LLM, give me a JSON. Make no mistakes.
So how exactly do you make your LLM output a JSON? What happens under the hood? And how do you make it reliable and fast?
Make no mistakes
Imagine, you have finally managed to set up the LLM inference for your application, and now it is even able to respond to you. And it can do so much stuff! But for most of these use cases, getting "just" text back is very limiting. In fact, in order to make most of the non-chatbot use cases work, you would need more structured info like JSON. So you just append to the prompt:
Remember to give me the output in JSON format. Make no mistakes.
As the JSON output gets longer and longer, somehow your super smart model fails from time to time. Apart from not getting the object keys right,
it appends the additional , at the end of the last key-value, which makes the parser complain. You might ask, is there a better way?
There is!
Being able to control what format exactly does your LLM produce is super valuable and technically super interesting. Let us thus take a deep dive into how you go past "make no mistakes" and how the inference engines do it reliably and fast.
Note: If you feel familiar with JSON schemas and GBNF, just skip into the section "Processing Grammars".
Autoretries
The first solution that comes to mind is just to employ some retry strategy at the message level. Essentially:
while True:
answer = llm(prompt)
if is_json(answer):
breakThis works. The only positive thing I have to say about it is that you can treat the LLM as a complete blackbox, which might be viable for some libraries (actually I believe this is what LangChain does). For the negatives, there are plenty:
- by being "unlucky" or employing smaller models, you can be looping for a very long time or forever, before reaching the desired output
- you're wasting an enormous number of tokens, by discarding whole messages, even though they might not be all wrong
- to be able to get a JSON, you need to construct or download a specific parser, which is not very extensible
So if you don't have to, just don't do this please. However, by looking more closely into the LLM, you can have a little bit more principled approach.
Constrained Sampling
There are two observations, which we can make.
First, LLMs generate outputs token by token. Usually you don't have to generate the whole answer to see that something is wrong. We can retry right away when the model makes the first error which is not in the right format. This way, we are not deleting the whole message, but just the last token:
answer = ""
while True:
token = llm.next_token(prompt + answer)
if token == "<eos>":
break
if is_partial_json(answer):
answer += tokenSecondly, the answer tokens don't appear out of the blue. Given a text, LLMs produce a probability distribution on the next token. Instead of simply sampling from the distribution immediately, we can start by setting the probability of all tokens leading to incorrect output to 0. This way, we are guaranteed to only sample (and thus output) a correct token. If we wanted just a number, we could do something like:
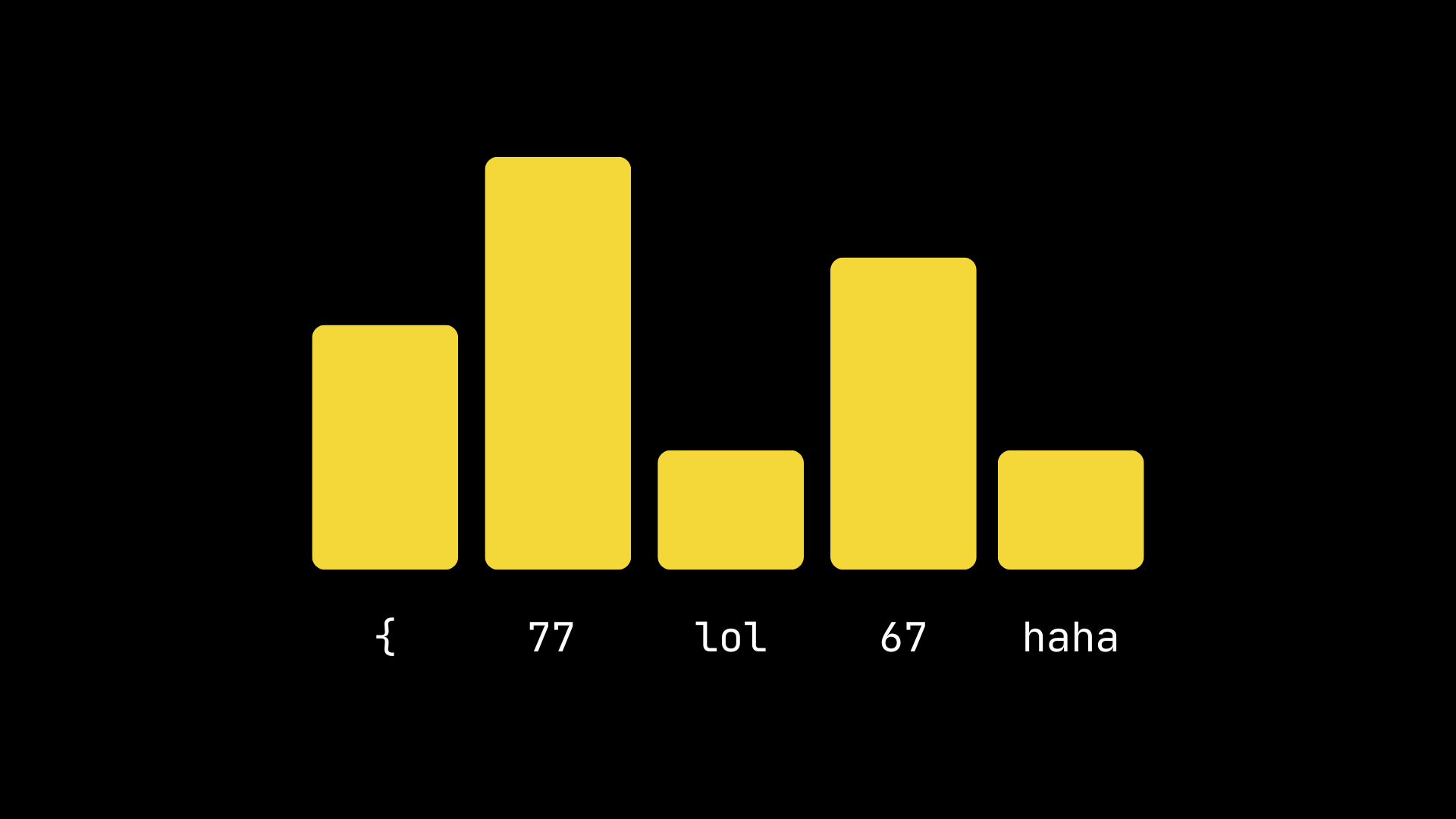
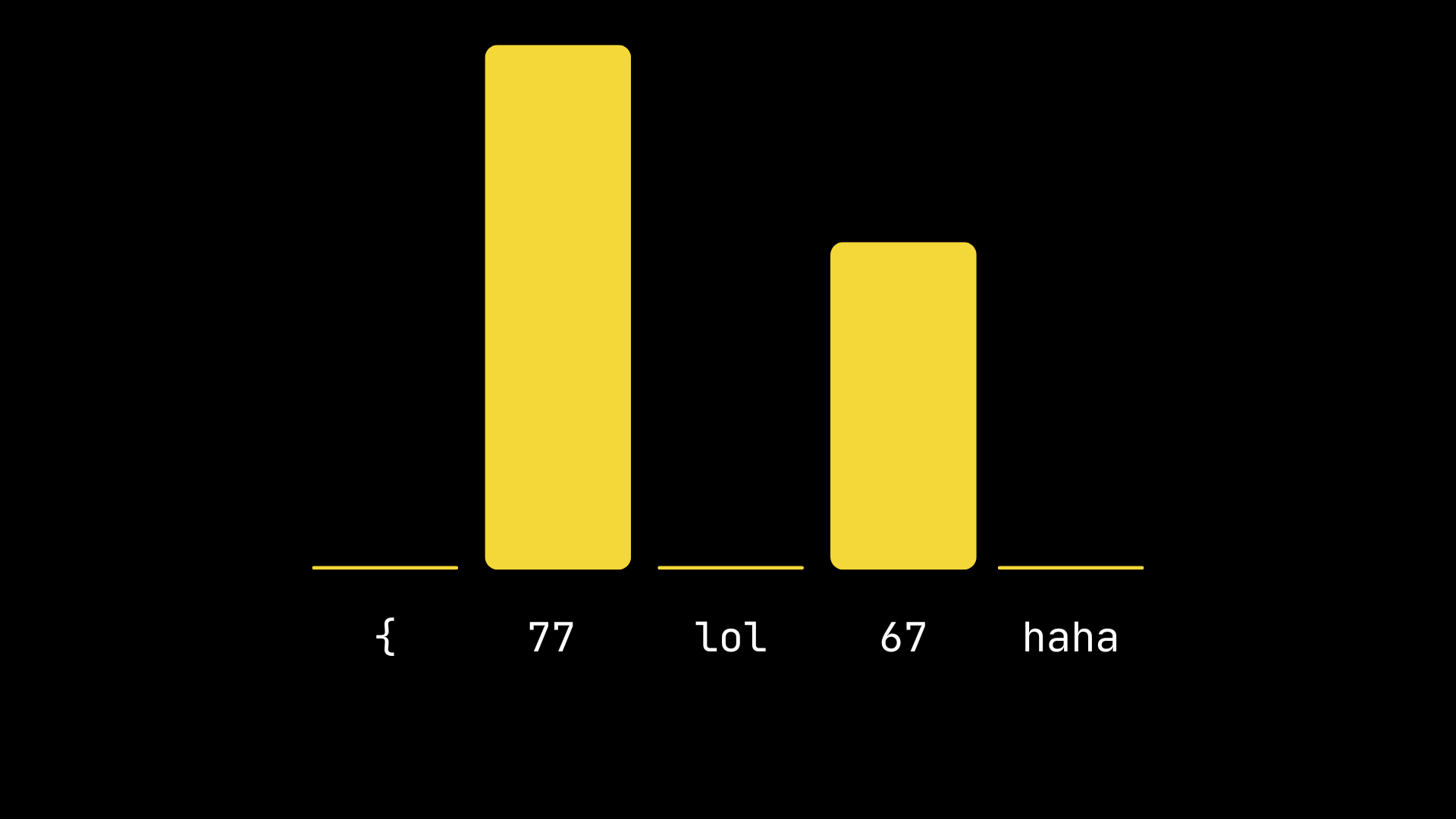
Technically, this process is called "masking". One more detail to address is that just shrinking the probability of the tokens we don't want to 0
would break the distribution property (we want the probabilities to sum to 1). In reality the solution is therefore to set the underlying
logits to -inf, which will result in turning the unwanted tokens' probabilities to 0, but slightly bumping the other tokens up.
The pseudocode then could look like this:
answer = ""
while True:
token = llm.next_token(
prompt + answer,
mask=possible_next_json_tokens(prompt + answer)
)
if token == "<eos>":
breakSo even though we are still looping, there is no discarding going on - we can't be unlucky and we are not wasting compute. The hard part is now how to specify the possible next tokens, generally called "mask", and how to do that quickly, so the LLM is not waiting for us.
Specifying the Format
What exactly is JSON? To construct the mask, we have to be able to answer this token by token.
One of the great ways that we are able to precisely specify some text format is regexes.
Unfortunately, as the name suggests, regexes are made for specifying regular languages, which JSON is not.
With the (basic set of) regex features, you won't be able to for example guarantee that any opened { will also be closed by a corresponding }.
A more fitting way for this use case is employing JSON schemas. If you don't know JSON schemas, they are essentially a metalanguage on top of JSON, to specify what JSON format you expect. This way, we can say for example:
{ "type": "object" }to get any JSON object. Or, if you want something more specific:
{
"type": "object",
"properties": {
"name": "string",
"age": "integer"
}
}This is a more concrete specification and some of the inference engines/APIs accept JSON schemas directly! (e.g. Claude API, OpenAI API, vLLM, etc.) On the other hand, we did not really move towards a "lower level" specification of what we want; JSON schemas are still quite abstract.
Note that with all of the formats (regexes, JSON schemas, grammars) it is still important to tell the LLM what it is that you expect in the answer. The LLM does not know it is being constrained, so if you do not tell it what you expect, the token distributions will stay as if the output was not constrained, possibly hurting performance.
Grammars to the Rescue
More low-level and general specification can be achieved by passing in grammars, specifically Context-Free Grammars (CFGs). Grammars are precise descriptions on what strings can be generated - they are typically utilized in fields like programming language theory (parsers), linguistics, and some parts of theoretical computer science. In the inference engines they typically underlie processing all of the constrained generation, whether it is specified by regexes, JSON schemas or "manually". They also cover most of the wide-spread structured formats used, such as Python syntax.
Example of such a grammar could be:
INT ::= "-"? [0-9]+
which provides an INT rule for generating any signed integer. These rules can then be composed in a way where they "call" each other, to form larger structures:
ROOT ::= "{ \"name\":" STRING ",\"age\":" INT "}"
STRING ::= "\"" [^"]* "\""
INT ::= "-"? [0-9]+
which is a very simplified grammar for the JSON schema we discussed earlier. The STRING rule consumes any sequences without ",
and ROOT just acts as an entrypoint and assembles everything together. This exact format of writing down the grammars is known as GBNF
and underlies the constrained generation in llama.cpp, but also other engines.
If you want to read more about it, I recommend starting here.
With grammars in place, we have done the work on the "user's" side - we have a general and exact specification from the user of what they actually want. Still, these are not the token masks. Now, we will dive deeper into how the inference engines convert the grammars into masks (fast).
Processing Grammars
To understand how the grammars then translate into masks, we will need a bit of theory under our belts. Let us start simple: with a simple integer rule and a whole string upfront, for which we just decide if it corresponds to the grammar. Starting with the INT rule:
INT ::= "-"? [0-9]+
We remove the syntactic sugar:
INT ::= "-" [0-9]+ | [0-9]+
and replace the + and * with recursion:
INT ::= "-" DIGITS | DIGITS
DIGITS ::= [0-9] | [0-9] DIGITS
This gets us simplified expressions, which are easier to work with. If you feel a bit lost on what actually happened, we just made a few regex transformations, which are equivalent to what we had before.
Now, to produce the masks, we will use a machine with a stack (or in the right terms "pushdown automaton", PDA). If you don't know what a stack is, you can think about it like an array, where from one end, we are allowed to append and pop elements. In our case, these will be characters (in practice bytes) and names of the rules (INT, ROOT, STRING, ...).
Top-Down Parsing
To make things a little bit easier, we will again focus on a simpler case - we won't generate strings from tokens yet. Instead, we will be given a whole string at the start, and only be tasked with checking if such a string can be generated with the current grammar or not. The following approach is usually called top-down parsing and again, has been here since the 70s.
We will continue with the following four simple rules:
- Start with appending the root rule to the stack.
- If there is a rule at the top, pop it and replace it with one of its definitions.
- If there is a character at the top, which matches the input, consume both. Otherwise get stuck and reject.
- If both stack and input are empty, accept.
To illustrate how this would go, look at the INT rule and input -1234. First, the stack is empty, so we proceed with (1).
![stack: [INT], string: -1234](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-1.jpeg)
As the top is a rule, we follow with (2). How do we know which definition to choose from? For now, let's pretend the machine just knows:
![stack: ["-", DIGITS], string: -1234](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-2.jpeg)
Applying rule (3), as the top is a character which matches the input.
![stack: [DIGITS], string: 1234](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-5.jpeg)
Then, nothing new happens. We just go by the previous rules (2, 3, 2, 3).
![stack: [[0-9], DIGITS], string: 1234](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-6.jpeg)
![stack: [DIGITS], string: 234](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-7.jpeg)
![stack: [[0-9], DIGITS], string: 234](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-8.jpeg)
![stack: [DIGITS], string: 34](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-9.jpeg)
![stack: [[0-9], DIGITS], string: 34](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-10.jpeg)
![stack: [DIGITS], string: 4](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-11.jpeg)
![stack: [[0-9]], string: 4](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-12.jpeg)
Until arriving at the empty stack and empty input. Well done! We can apply rule (4) and accept.
![stack: [], string: empty](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-14.jpeg)
This way we know the string conforms to the grammar specified. If we were parsing non-integer input, like .677,
we would arrive at this state:
![stack: [[0-9], DIGITS], string: .677](/assets/images/blog/2026/llm-give-me-a-json/top-down-parsing-15.jpeg)
As both are characters (or character ranges) and don't match, we are forced to reject the input.
Hopefully, now you have an idea of how you would implement such an approach. The last two problems we have are:
- We can consume whole strings, but LLMs produce tokens.
- How does the machine just know which definition to choose?
How exactly you solve these problems then depends on the particular grammar library you use. In the following, I will describe how llama.cpp does this.
From Whole Strings to Masks
Adapting to strings is now easier than it looks. What we will do is simply run the top-down parsing for each token. The only exception to the previous algorithm is that we don't need to consume the whole input and the whole stack. What simply suffices is that we don't get stuck on the way. The result should be a distribution, containing only tokens conforming to the grammar.
There is however one small caveat. Imagine sampling from the following distribution:
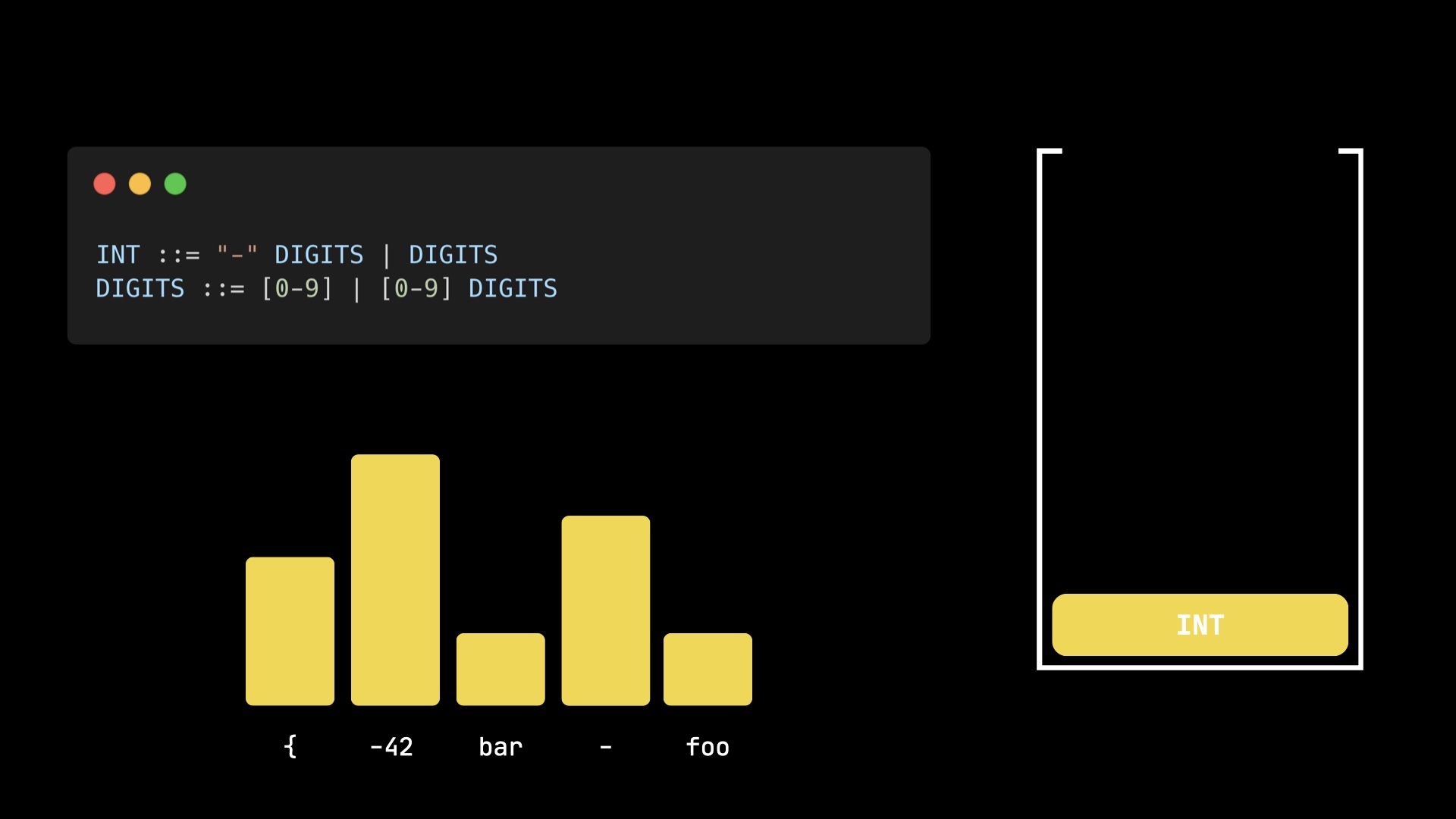
Initializing the stack again with the INT rule, and running the parsing, we end up just with -42 and -.
Now we sample, choosing the respective stack associated with the token. Let's say we sampled -42.
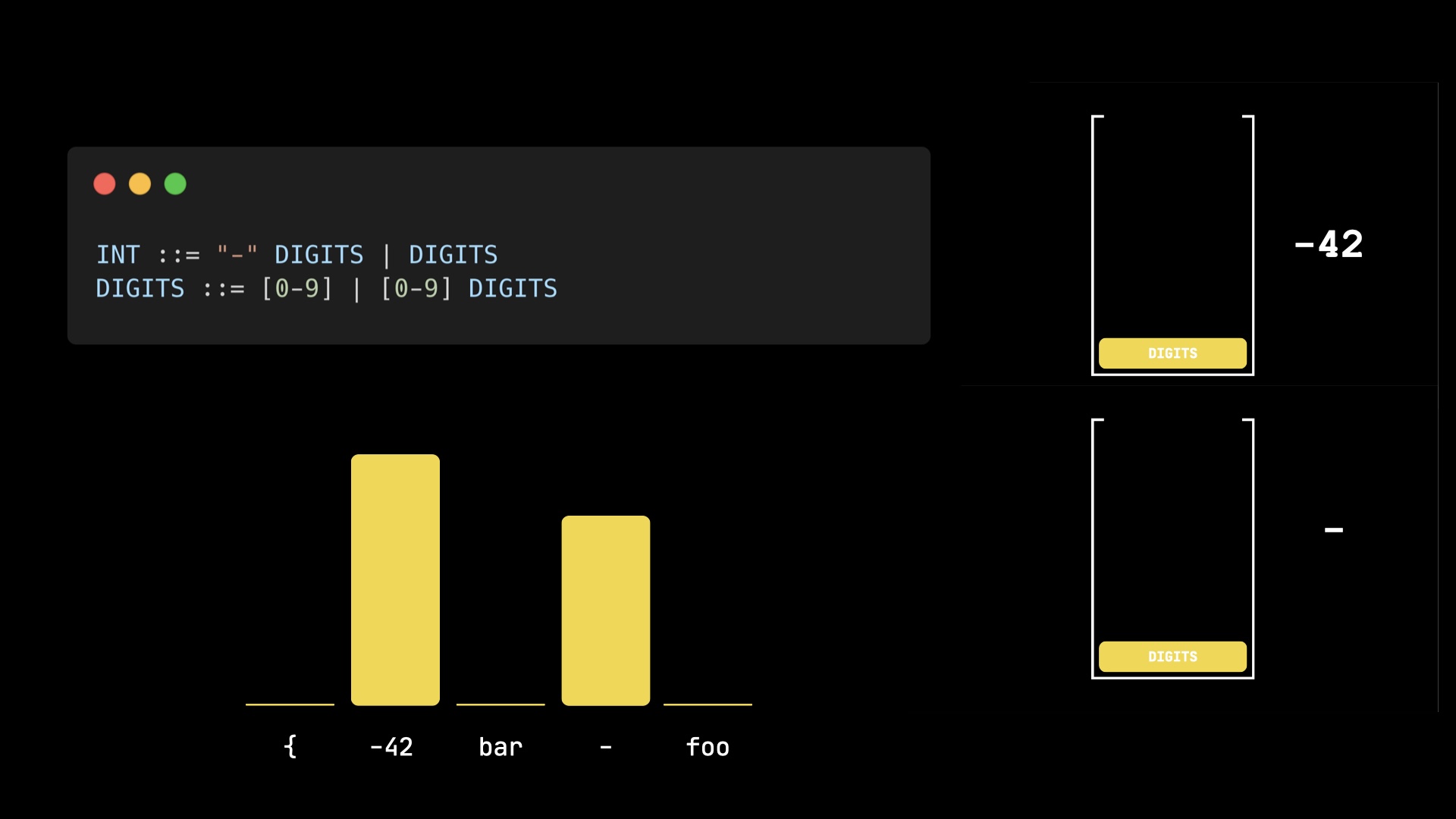
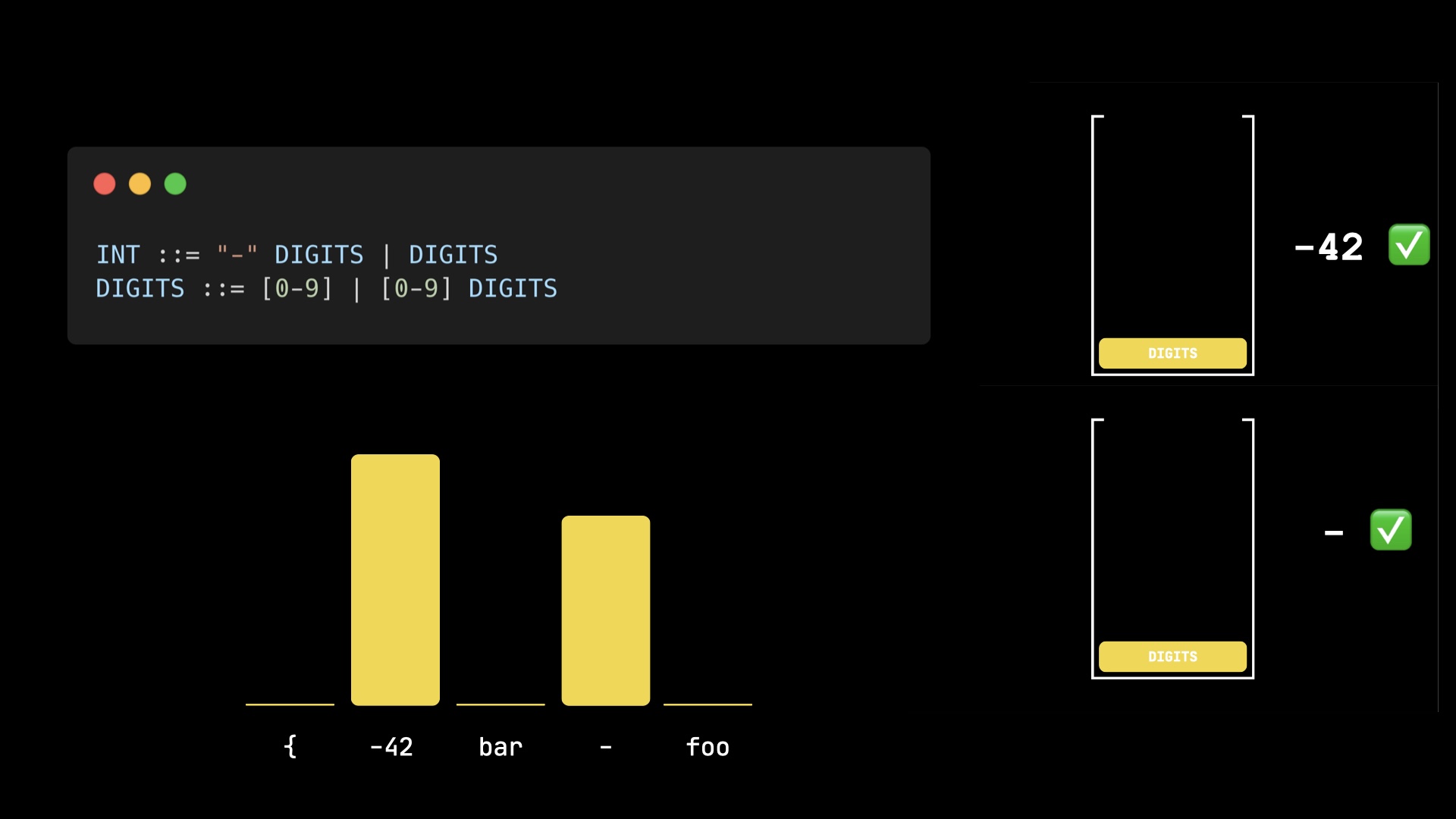
To continue and get the next token, we can't just reset the stack with the INT rule, but have to remember the position in the grammar and the corresponding stack.
Dealing with Non-determinism
You might still argue that we are dealing with this oracle machine, which somehow knows
if the rule [0-9] DIGITS or DIGITS is the right path. You would be right. Again, we can propose a simple solution.
Whenever there is a point where you have to make a decision, just go both ways.
Concretely, that means that when finding a rule like DIGITS | [0-9] DIGITS you just fork the current stack you have
and in one go with DIGITS, whereas the other one will have [0-9] DIGITS. Checking if a token goes through
is then about answering "Is there a stack which accepts?". Since all tokens are of finite length, you don't have to care
about infinite recursion (having a stack that would always expand DIGITS branch).
And that's it! Conceptually, this is how llama.cpp works!
Other Solutions
Bear in mind that the llama.cpp solution is more on the side of slow solutions, as it does everything
at inference time. In the end, you incur something like O(vocab_size * active_stacks) cost,
as you are keeping stacks for each token and for each different route through the grammar.
With current vocab sizes (100k+) and longer grammars, that can be just incredibly time-consuming.
Certainly, better solutions like XGrammar or LLGuidance exist.
The main problem with llama.cpp is, that we are doing a lot of work per step. Generally, smart precomputation is where you would go next.
If you however would have to choose a solution yourself, consider this graph:
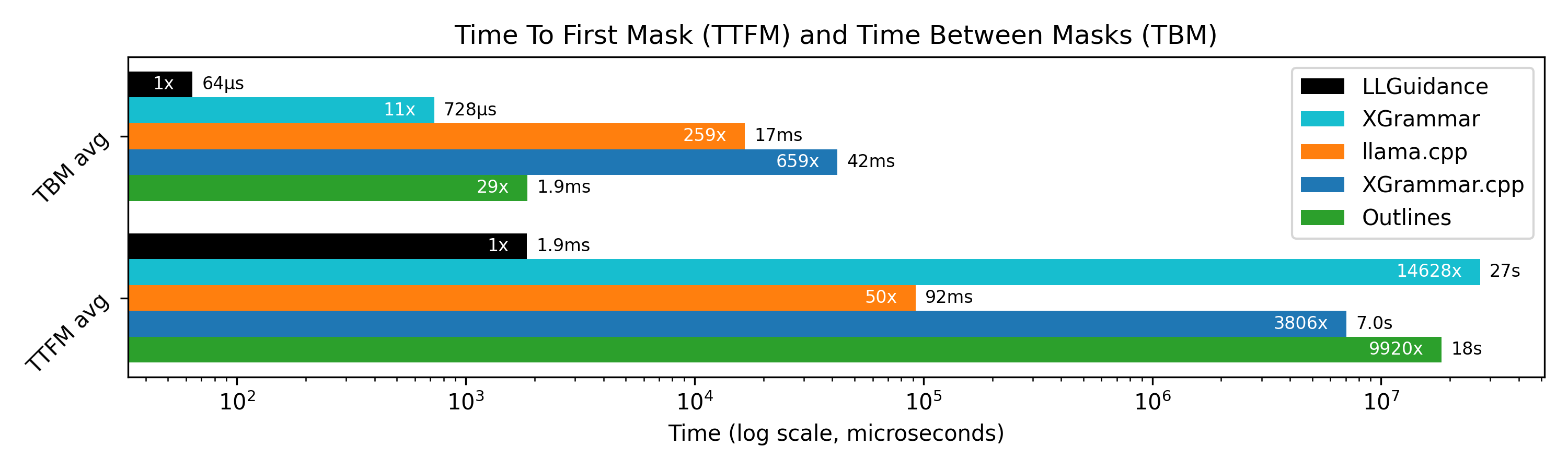
Source: guidance-ai/jsonschemabench — MaskBench benchmark
Clearly, there is a tradeoff going on. Engines like XGrammar and Outlines, which choose more precomputation, suffer from long "loading" times (shown as TTFM). On the other hand, llama.cpp does little precomputation, but then is generally slower per step (shown as TBM). And then there is llguidance, which seems to excel at both.
How Do We Use It
A few weeks ago, we decided to integrate NobodyWho with LLGuidance. This way, we get all of the benefits. Now, you can simply:
- pass in regex,
- pass in JSON schema,
- and pass in grammars. All wrapped nicely in an API, which is just as simple as it should be:
from nobodywho import Chat, SamplerPresets
sampler = SamplerPresets.constrain_with_regex(r"yes|no")
chat = Chat('./model.gguf', sampler=sampler)
answer = chat.ask("Is the sky blue?").completed()
print(answer) # yes!Conclusion
I very much like how constrained generation is a new problem, where we were able to apply existing theory to solve it in a nice, tractable way. I feel like that does not happen as often as it should.
At this point you know why:
- you should not do auto-retries, if you absolutely don't have to,
- having to sample other formats than JSON is not the end of the world, as you have grammars,
- there is a tradeoff between precomputation and per-step work with constrained sampling.
If you want to dive even deeper, I would go for:
- reading this incredible blog post about how LLGuidance is built,
- looking at the outlines paper to understand what you might cache before generating,
- or xgrammar paper which has nice insights into what is good to precompute.
Did you like this post? Consider giving us a star! That would mean a lot.
Thanks for reading!
This post was written entirely by a human. No words were made up by the machine.
Who We Are
We're NobodyWho, a local inference library, which enables running small models on edge-devices. We value open-source code, control over your models, solid software engineering, standardization and making simple things simple. All of which is missing in today's AI world. Running a model with us is as easy as:
from nobodywho import Chat
chat = Chat("model.gguf")
answer = chat.ask("Is water wet?").completed()
print(answer)If you value the same things, come and become a contributor or just download and test our library.
Published Jun 1, 2026